
The Contextual Data Model
This explanation is about the differences between tailored and contextual models. The article explains what a contextual model is, and what benefits it provides.
Definitions
Tailored model: Facts are entered into the database as they are discovered. Keep all data. Keep provenance. Domain model is defined by the application designer.
Contextual model: Facts are asserted within a context. Entities are targets for records and links. Records and links are made in the context they are collected. This provides the flexibility of conflicting times, facts, and relationships, which can make sense in one or more contexts but might also be explicitly rejected in other contexts.
Scenario
Arnold has a workout routine. He uses a heart rate monitor to measure max heart rate and a time series. He uses a notebook to write down the number of pushups he did. He also notes what his preferred drink post-workout is for the day.
He downloads the data from his heart monitor and collects all the data into a spreadsheet.
Can we replace the spreadsheet with a Datalog database?
Problem 1: When it entered the database is not when it happened.
Data can arrive at a database system after the time it was created. Data might arrive as part of manual data entry, or ETL from a third party. The time that the data applies is more interesting than when it was added to the database. The data might also be edited in the future if an error is discovered, or if previously omitted fields are updated.
Database time is not enough.
We must model time explicitly in our domain.
Problem 2: Conflicting facts
Arnold has always been a tea drinker. Last week, Arnold discovered coffee.
We must model “preferred drink” carefully! Arnold’s preference for tea or coffee will rarely change, but his daily workout “preferred drink” might. One day he drinks water, another day a shake, then orange juice. We must separate the storage of these preferences.
Arnold is also undecided as to whether tea or coffee is better for his health. He is researching scientific papers on the subject. Some say tea is better. Some say coffee is better. He needs to record conflicting facts to analyze and come to a decision.
“There is no truth. There is only perception.” – Gustave Flaubert
We must model conflicting facts.
Problem 3: Facts about relationships
The scientific papers link tea and coffee with their effects. But some papers are dubious and the links are tenuous at best. Arnold wants to preserve the source of these links in his database.
Refs are not enough.
We must model facts about relationships.
These 3 requirements show up in many domains. Especially when creating Diagrams.
The Contextual Datalog Model
Contextual Entities are no different from Epochal Entities. An identifiable thing with optional attributes and refs. An Entity usually has a name, title, or external id attribute.
Contextual facts about an Entity are stored in Records and Links.
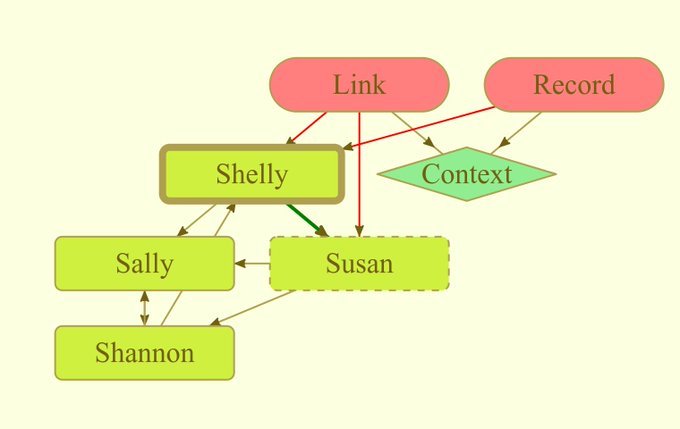
A Record must be of an Entity, and be in a Context. A Record may contain facts that union with the Entity to describe the entity.
A Link must be from one Entity to another Entity, and in a context. A Link must have an attribute, which is a valid connecting attribute between the source and target Entities, which unions with the source Entity. A Link may contain facts about the relationship.
A Context must have an as-of time that indicates temporal precedence. A Context must have a name.
Contexts, Records, and Links are epochal entities.
Contextual schema
Context
| Attribute | Spec |
|---|---|
| context/name | unique |
| context/of:entity | ref-one |
| context/at | value-one |
| context/extends:contexts | ref-many |
| Diagram specific Attributes | Spec |
|---|---|
| :context/styled-with:theme | ref-one |
| :context/groupings | value-many |
| :context/layout-algorithm | value-one |
| :context/layout-options:map-entries | ref-many |
- A diagram of a Group Entity.
- Notes about a Workout Entity.
- A summary of a Paper Entity.
Diagrams, notes, and summaries are interchangeable views of the context.
Record
| Attribute | Spec |
|---|---|
| :record/in:context | ref-one |
| :record/of:entity | ref-one |
| :record/context+entity | tuple |
| Diagram specific Attributes | Spec |
|---|---|
| :record/color | value-one |
| :record/weight | value-one |
| :record/shape | value-one |
- Emily is a Person Entity.
- A Record of Emily is added in the Context of a Sociogram of a Group Entity (Grade 3).
- The union of all Records of Emily is equivalent to an Epochal Entity representation of Emily.
Link
| Attribute | Spec |
|---|---|
| :link/in:context | ref-one |
| :link/attr | value-one |
| :link/from:entity | ref-one |
| :link/to:entity | ref-one |
| :link/context+from+attr+to | tuple |
| Diagram specific Attributes | Spec |
|---|---|
| :link/color | value-one |
| :link/weight | value-one |
| :link/label | value-one |
- Emily is friends with Lisa.
- A Link is created in the Context of a Sociogram from Emily to Lisa.
- The Link has an attr of person/likes:person so it can be reduced down to a ref. Thus Links from Emily union with Emily by attr.
Benefits
Changes to one diagram do not affect another diagram (unless explicitly sharing contexts across them).
Contexts can be ordered and unioned to give the Epochal Model.
Can see the union of all diagrams.
Can query alternative subsets of the union.
Contexts can be selected to provide isolated views.
Applications
Project management data is largely in situ, does it need contextual records?
Example 1: What if you wanted estimates for tasks to be done to two levels of detail. Epics and tasks might have a high-level estimate and a high-fidelity estimate. Those estimates might occur in different contexts where the scope is fully discovered or only partially known. You could model this with 2 fields for an estimate, or you could model it as a context.
Example 2: What if you wanted to develop 2 roadmaps to present to leadership with different team assignments and order of execution?
The Hummi database vision
Why Contextual Datalog Model is important for Hummi
Users can create their own schema (Can choose some sensible templates).
Users own their data (Choose between Local Storage/IndexDB/true local/Firebase/Third Party).
REPL + Query builder + Visualizations
Import and sync data from a whole heap of sources
Query locally not remotely
Appendix
;; Abstract map storage (supports nesting) :map-entry/key value-one :map-entry/key-name value-one :map-entry/key-namespace value-one :map-entry/value value-one :map-entry/value:map-entries ref-many
:source/relation:target is preferable over :source:relation/target Because the former keeps entities well defined in a single namespace (source). It also makes plain old maps more sensible, as the relationship is usually more important in naming than the target type, and is often necessary to disambiguate.
Theoretical limitation of both: the source can be fully qualified, but the target cannot. This is not enforced though, keywords “work” when dot appears in the name, even though the documentation says they shouldn’t be allowed. You could put relation at the end, but I don’t recommend it.
References
RDF Reification A triple can itself be one of the slots of another triple Widen the triple (transactions are a special case of widening) Give triples an identifier